The availability of sophisticated AI models can help organizations reduce significantly the intimidating amount of resources a data science project can require. Let’s see how organizations can tackle machine learning challenges and operations with Azure Machine Learning.
Machine learning challenges and machine learning operations
Maintaining AI solutions typically requires machine learning lifecycle management to document and manage data, code, model environments, and the machine learning models themselves. You need to establish processes for developing, packaging, and deploying models, as well as monitoring their performance and occasionally retraining them. And most organizations are managing multiple models in production at the same time, adding to the complexity.
To cope effectively with this complexity, some best practices are required. They focus on cross-team collaboration, automating and standardizing processes, and ensuring models can be easily audited, explained, and reused. To get this done, data science teams rely on the machine learning operations approach. This methodology is inspired by DevOps (development and operations), the industry standard for managing operations for an application development cycle, since the struggles of developers and data scientists are similar.
Azure Machine Learning
Data scientists can manage and execute machine learning DevOps from Azure Machine Learning, a platform by Microsoft to make machine learning lifecycle management and operations practices easier. Such tools help teams collaborate in a shared, auditable, and safe environment where many processes can be optimized via automation.
Machine learning lifecycle management
Azure Machine Learning supports end-to-end machine learning lifecycle management of pretrained and custom models. The typical lifecycle includes the following steps: data preparation, model training, model packaging, model validation, model deployment, model monitoring and retraining.
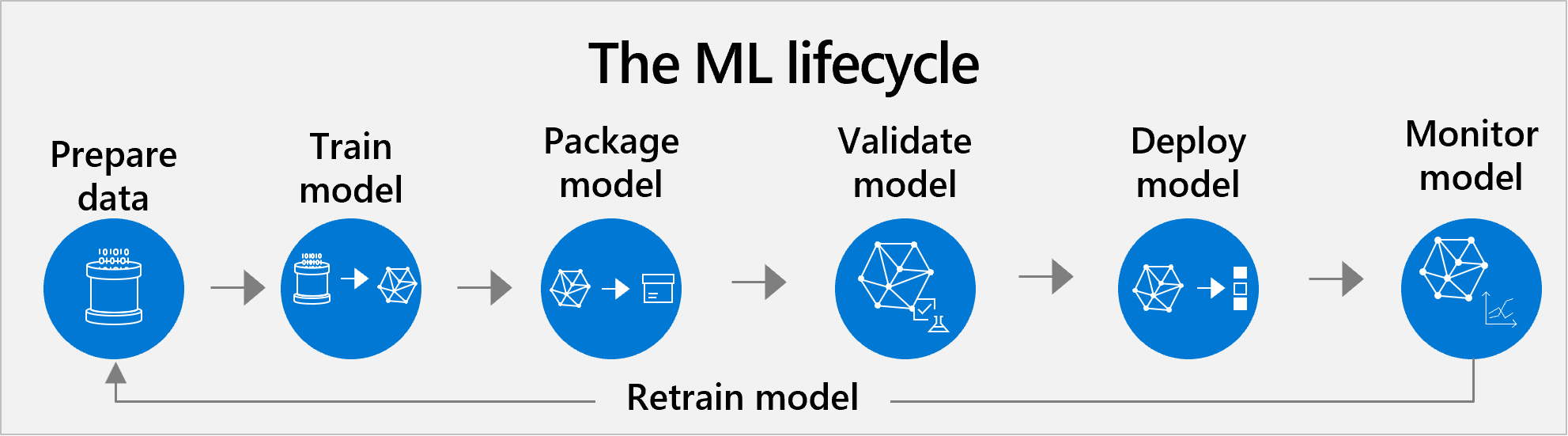
The classic approach covers all the usual steps of a data science project.
- Prepare dataset. AI starts with data. First, data scientists need to prepare data with which to train the model. Data preparation is often the biggest time commitment in the lifecycle. This task involves finding or building your own dataset and cleaning it so it’s easily readable by machines. You want to make sure the data is a representative sample, that your variables are pertinent for your goal, and so on.
- Train and test. Next, data scientists apply algorithms to the data to train a machine learning model. Then they test it with new data to see how accurate its predictions are.
- Package. A model can’t be directly put into an app. It needs to be containerized, so it can run with all the tools and frameworks its built on.
- Validate. At this point, the team evaluates how model performance compares to their business goals. Testing may return good enough metrics, but still the model may not work as expected when used in a real business scenario.
- Repeat steps 1-4. It can take hundreds of training hours to find a satisfactory model. The development team may train many versions of the model by adjusting training data, tuning algorithm hyperparameters, or trying different algorithms. Ideally the model improves with each round of adjustment. Ultimately, it’s the development team’s role to determine which version of the model best fits the business use case.
- Deploy. Finally, they deploy the model. Options for deployment include: in the cloud, on an on-premises server, and on devices like cameras, IoT gateways, or machinery.
- Monitor and retrain. Even if a model works well at first, it needs to be continually monitored and retrained to stay relevant and accurate.
Leave a Reply