Most nontrivial web applications need to reliably run operations on data, such as create, read, update, and delete (CRUD). They also need to persist any changes made by these operations between application restarts. Although there are various options for persisting data in .NET applications, Entity Framework (EF) Core is a user-friendly solution and a great fit for many .NET applications.
Understand EF Core
EF Core is a lightweight, extensible, open source, and cross-platform data access technology for .NET applications.
EF Core can serve as an object-relational mapper, which:
- Enables .NET developers to work with a database by using .NET objects.
- Eliminates the need for most of the data-access code that typically needs to be written.
EF Core supports a large number of popular databases, including SQLite, MySQL, PostgreSQL, Oracle, and Microsoft SQL Server.
The model
With EF Core, data access is performed by using a model. A model is made up of entity classes and a context object that represents a session with the database. The context object allows querying and saving data.
The entity class
In this scenario, you’re implementing a pizza store management API, so you use a Pizza entity class. The pizzas in your store have a name and a description. They also need an ID to allow the API and database to identify them. The Pizza entity class that you use in your application identifies pizzas:
C#Copy
namespace PizzaStore.Models
{
public class Pizza
{
public int Id { get; set; }
public string? Name { get; set; }
public string? Description { get; set; }
}
}
The context class
This application has only one entity class, but most applications have multiple entity classes. The context class is responsible for querying and saving data to your entity classes, and for creating and managing the database connection.
Perform CRUD operations with EF Core
After EF Core is configured, you can use it to perform CRUD operations on your entity classes. Then, you can develop against C# classes, delegating the database operations to the context class. Database providers in turn translate it to database-specific query language. An example is SQL for a relational database. Queries are always executed against the database, even if the entities returned in the result already exist in the context.
Query data
The context object exposes a collection class for each entity type. In the preceding example, the context class exposes a collection of Pizza objects as Pizzas. Given that we have an instance of the context class, you can query the database for all pizzas:
C#Copy
var pizzas = await db.Pizzas.ToListAsync();
Insert data
You can use the same context object to insert a new pizza:
C#Copy
await db.pizzas.AddAsync(
new Pizza { ID = 1, Name = "Pepperoni", Description = "The classic pepperoni pizza" });
Delete data
Delete operations are simple. They require only an ID of the item to be deleted:
C#Copy
var pizza = await db.pizzas.FindAsync(id);
if (pizza is null)
{
//Handle error
}
db.pizzas.Remove(pizza);
Update data
Similarly, you can update an existing pizza:
C#Copy
int id = 1;
var updatepizza = new Pizza { Name = "Pineapple", Description = "Ummmm?" };
var pizza = await db.pizzas.FindAsync(id);
if (pizza is null)
{
//Handle error
}
pizza.Description = updatepizza.Description;
pizza.Name = updatepizza.Name;
await db.SaveChangesAsync();
Use the EF Core in-memory database
EF Core includes an in-memory database provider that can be used to test your application. The in-memory database provider is useful for testing and development, but it shouldn’t be used in production. In the next unit, you’ll use the in-memory database provider to create a database and perform CRUD operations on it.
https://lernix.com.my/mysql-database-training-courses-malaysia
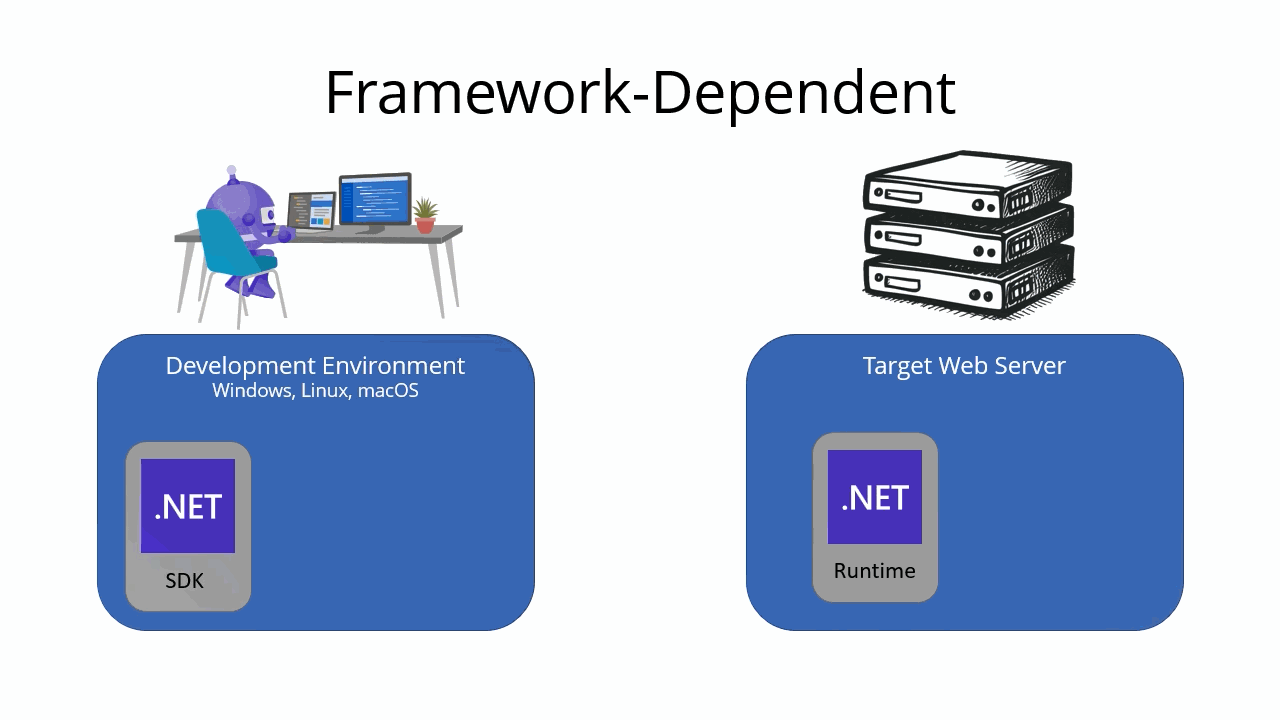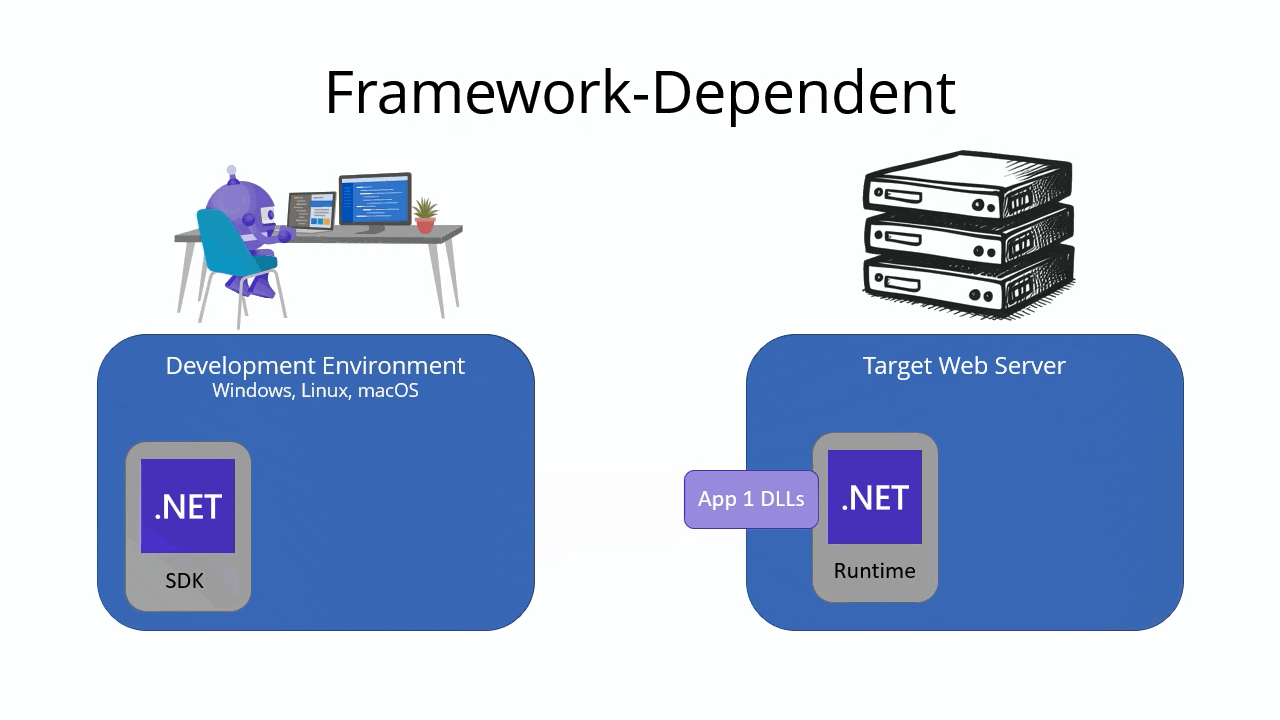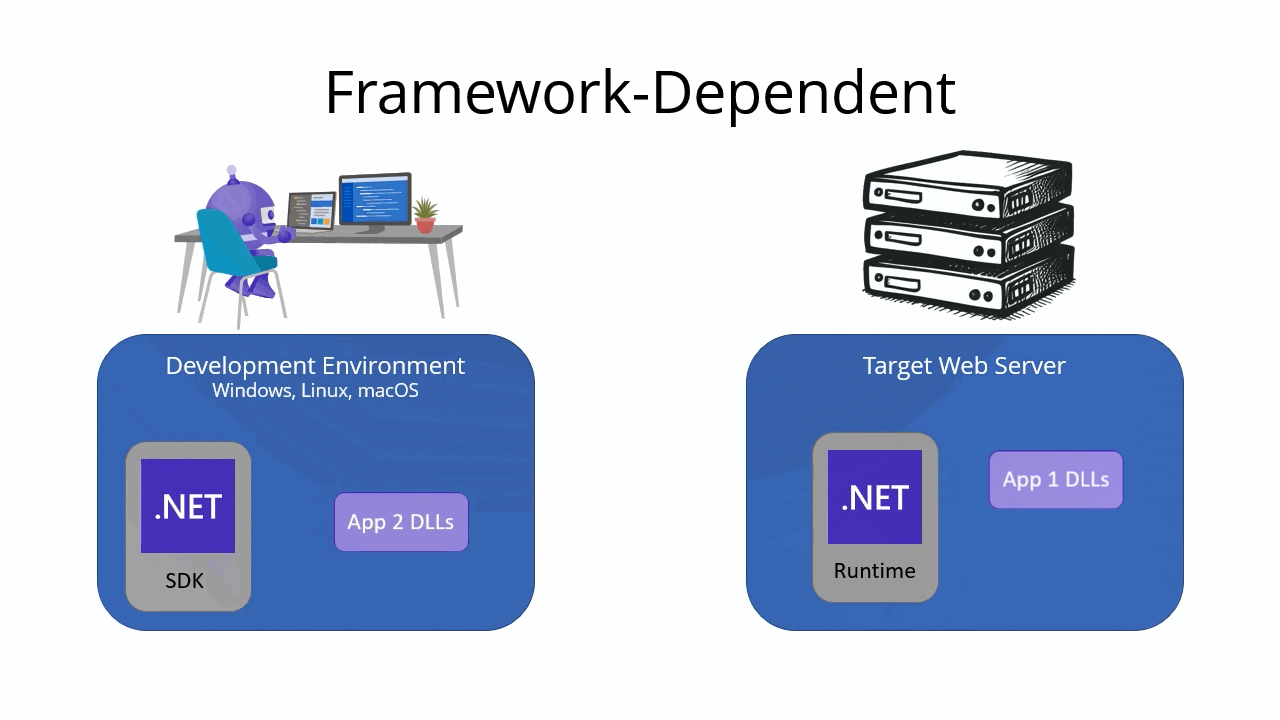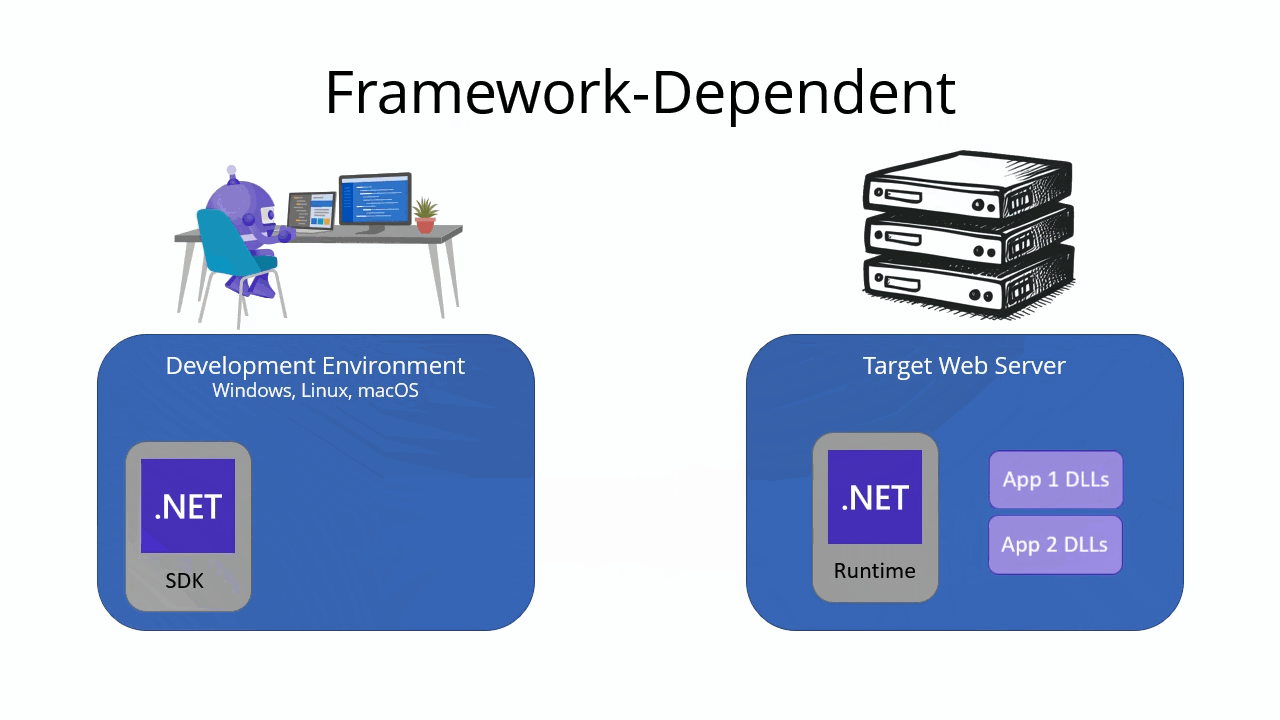
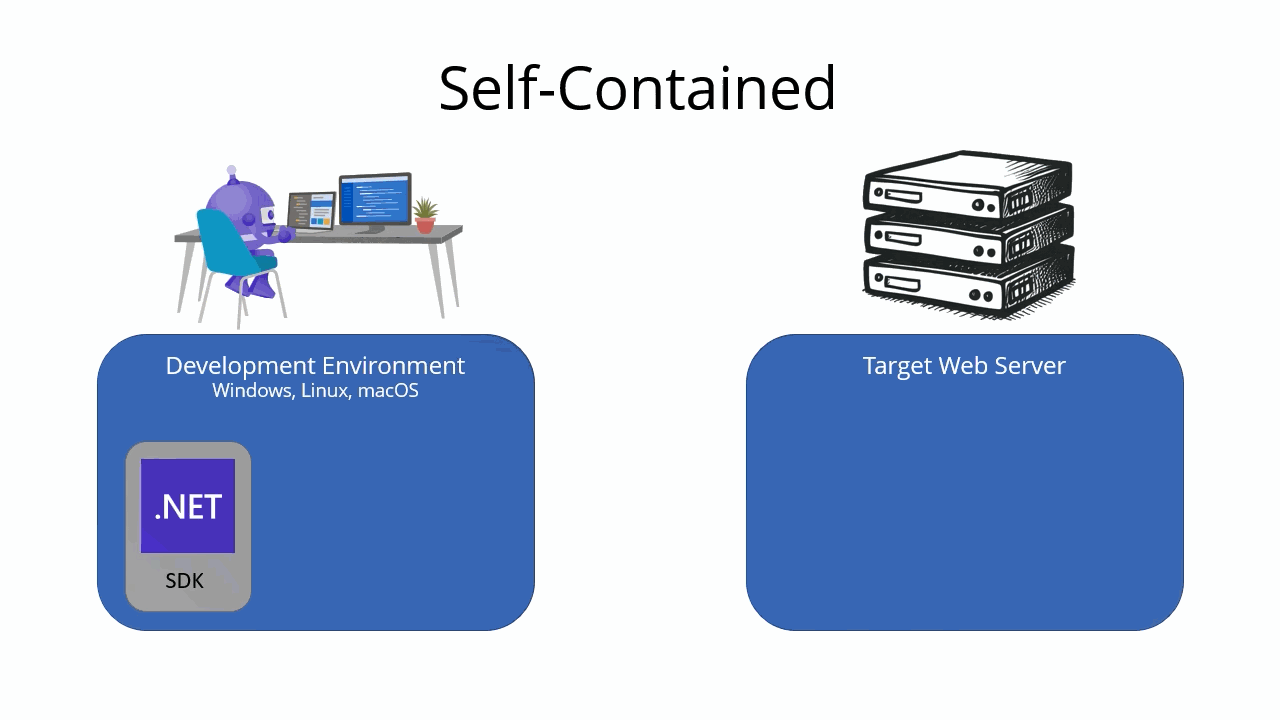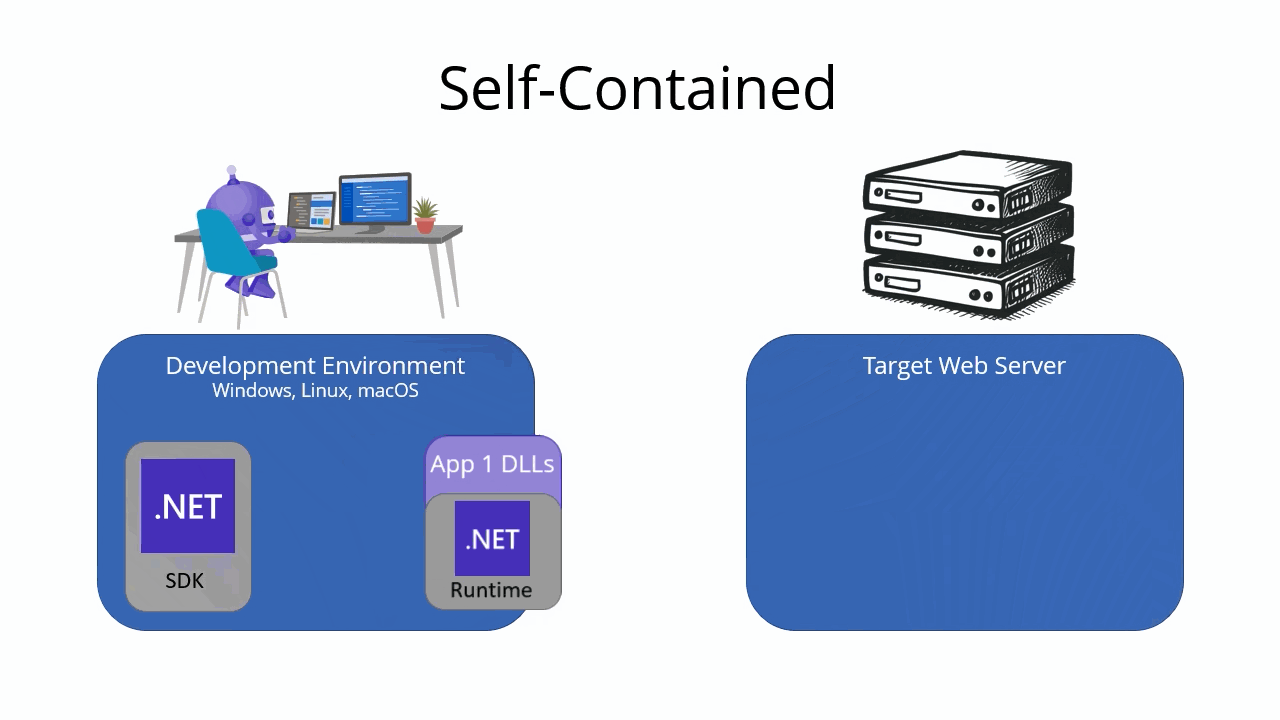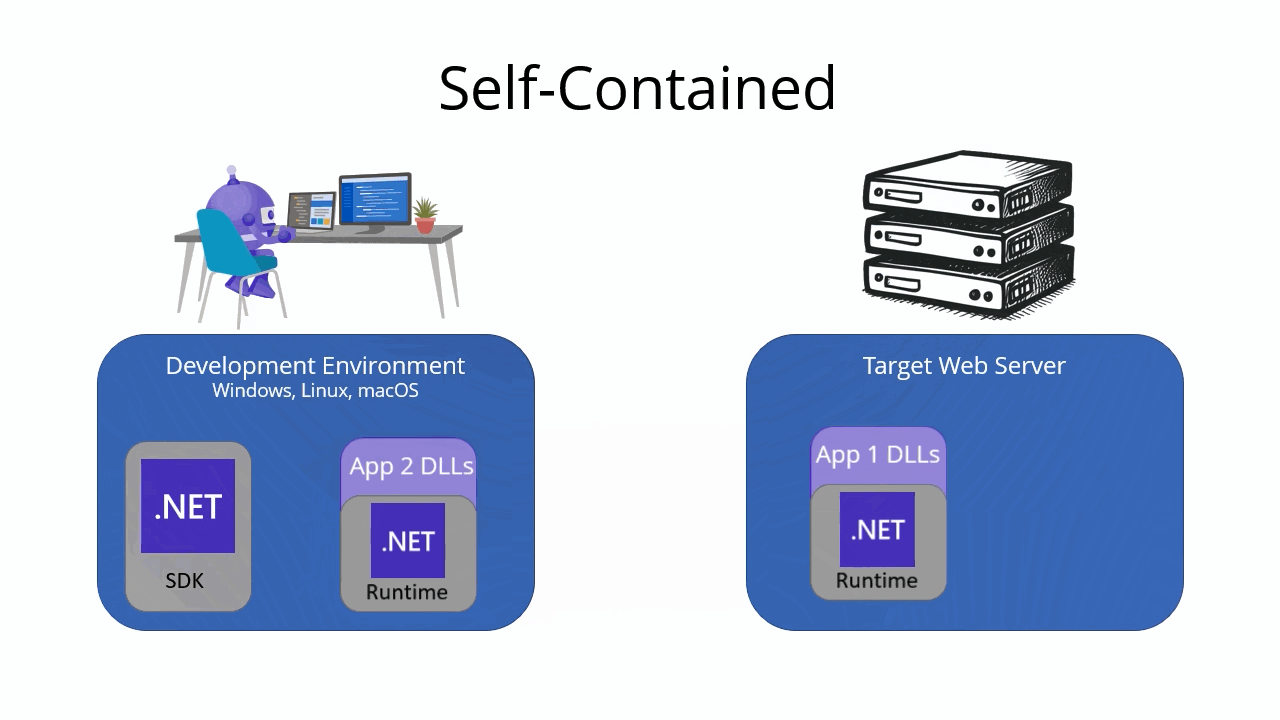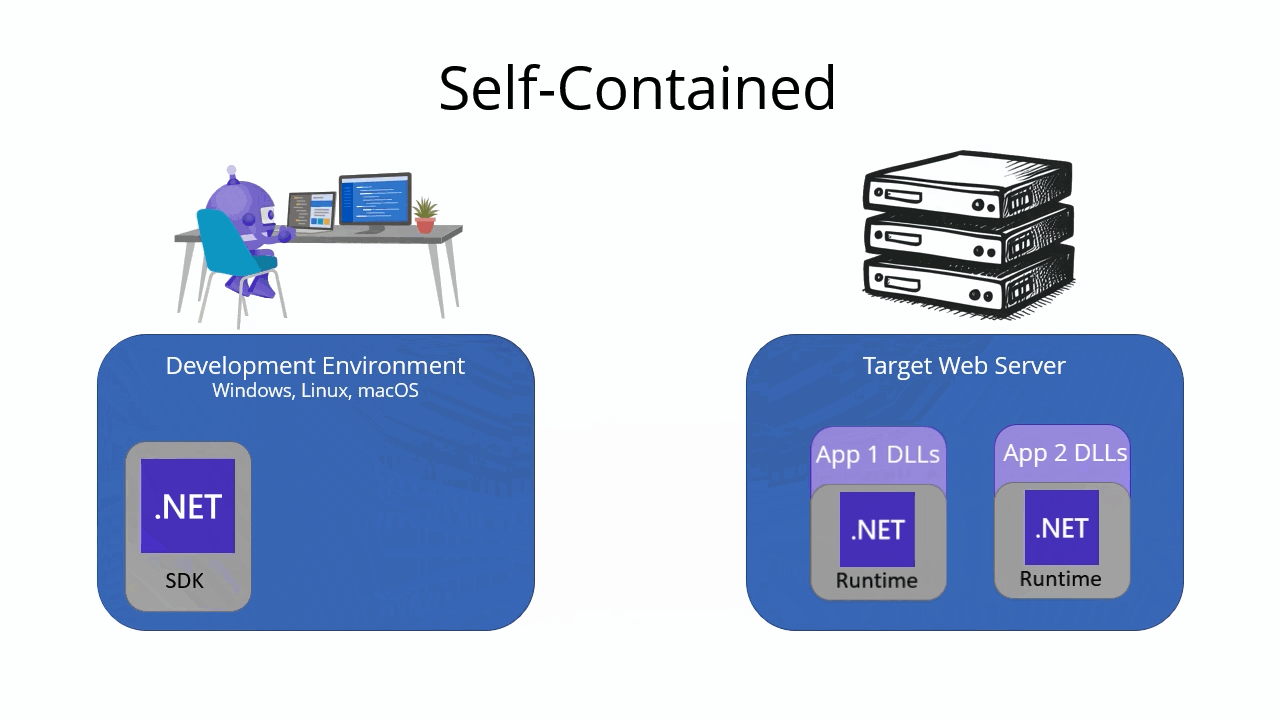
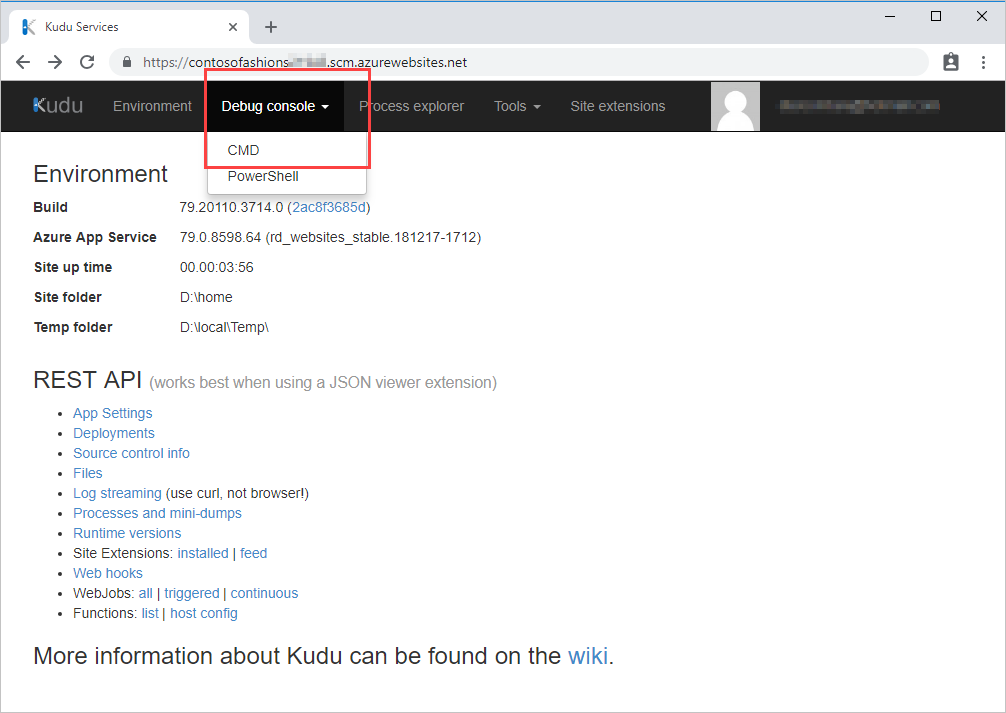
 For Linux apps, select the download link on the Environment page.
For Linux apps, select the download link on the Environment page.